
Between July 28th and August 2nd, the annual international conference of the Association for Computational Linguistics (ACL'19) took place in Florence, Italy. Webintepret was present at the conference by participating in the 4th Conference on Machine Translation co-hosted within the ACL’19. In particular, same as last year, we participated on the parallel corpus filtering competition open to research institutions worldwide.
Parallel corpus filtering tackles the problem of cleaning noisy data to obtain a clean parallel corpus suitable to train accurate machine translation systems. The organisers of the task posed the challenge of assigning sentence level quality scores for very noisy corpora of sentence pairs crawled from the web, with the goal of sub-selecting 2% and 10% of the highest-quality data to be used to train machine translation systems. This year, the task tackled the low resource condition of Nepali– English and Sinhala–English. Eleven entities from companies such as Facebook, national research labs such as the USA Air Force Research Lab, and various universities participated in this task.
The organisers pose the problem under a challenging low-resource conditions including Nepali and Sinhala languages. They provide parcitipants with a very noisy 40.6 million-word Nepali-English and a 59.6 million word Sinhala-English corpora. Both raw corpora were crawled from the web as part of the Paracrawl project. Participants are asked to select a subset of sentence pairs that amount to (a) 5 million, and (b) 1 million English words. The quality of the resulting subsets is determined by the quality of a statistical and a neural Machine Translation (MT) systems trained on the selected data. The quality of the translation systems is measured on a held-out test set of Wikipedia translations. Despite the known origin of the test set, the organisers make explicit that the task addresses the challenge of data quality and not domain relatedness of the data for a particular use case.
The main idea explored for our submission is to minimise the amount of unseen events for the model. In MT, these unseen events are words or sequences thereof. These unseen events result in a loss of model coverage and, ultimately, of translation quality. The main difference of our submission respect to previous approaches is that we do not rely on an in-domain corpus to identify underrepresented events. Instead, we look for the subset of sentences that provide the most coherent coverage among themselves. One of the advantages of this approach is that it does not rely on pre-trained models requiring additional data to train. This characteristic fits perfectly with the focus on low-resource languages of this year’s task.
Our approach involves 3 consecutive steps:
- Filter out some of the pairs in the noisy corpus according to several heuristic rules. For instance, we filter out sentence pairs containing sentences in other languages than Nepalese-English or Sinhala-English.
- For the remaining pairs, we sort them according to different criteria:
a) Eight different orderings based on coverage ranking measuring the amount of valuable information contained on each sentence of the pair.
b) Four different orderings based on how the sentences in the pair maintain the meaning of each other - We combine these orderings in order to obtain the final quality score of each sentence pair as required by the organisers.
All the details of our submission can be found in our participation paper (González-Rubio, 2019), and a less technical description in the official poster presented at the conference.
The following plots display the performance of the the different participants by showing their combined statistical (SMT) and neural (NMT) scores. We present such scores for the four official settings in the competition. Among them, Webinterpret reached two fourth places, one fifth and one sixth place.
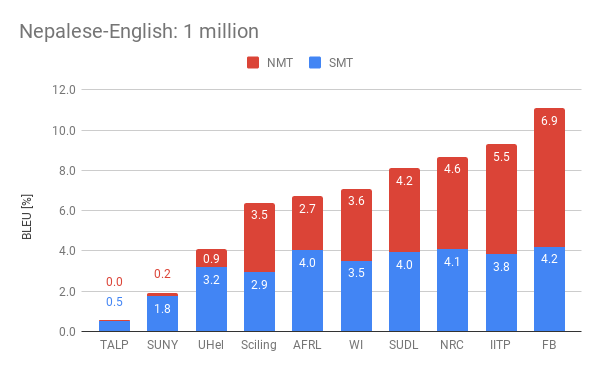
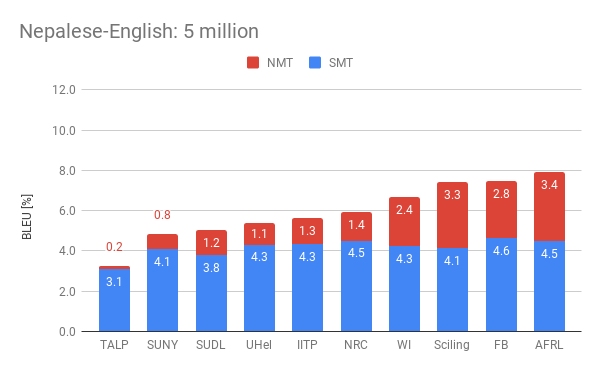
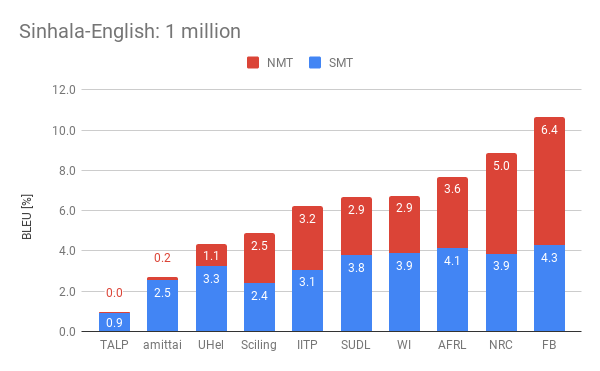
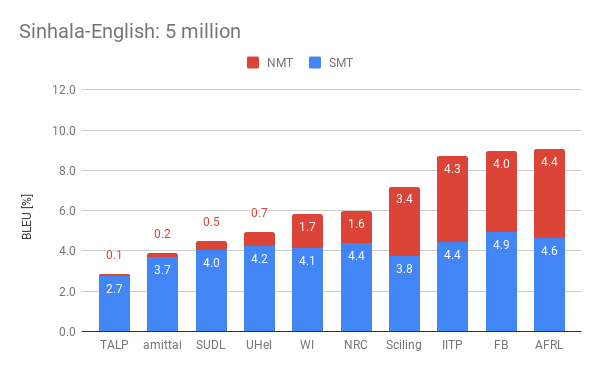
One interesting observed effect is the reduced performance of neural MT in the presence of more data. The organisers observed this on all the submissions and perform an interesting analysis about the potential causes for this.
Our submission (WI) lays in the upper half among the best submission of the different participants. Regarding Nepalese-English, it scored an aggregated of 7.1 and 6.7 points for the 1 million and 5 million conditions respectively. This represent respectively about a 64% of the best result submitted for the 1 million condition, and about a 85% of the best result for the 5 million condition. As for the Sinhala–English condition, we scored 6.8 and 5.8 points which represent a 64% of the best results respectively.

