
Approach and techniques used to build a product similarity catalog
The e-commerce industry is a complex world, and each of its elements is a challenge within itself. One of those key elements seems to be the most obvious one - the seller and their products.
Typically e-commerce products are described by their titles, attributes, photos, categories and of course the price. In addition, each of these products can have its own sales history, statistics on visibility in searches and user clicks. But what if this information is missing? Such as when a product is new and there is no sale yet or its category, material or weight is unknown?
At Webinterpret, we work with millions of products that come from various source, are sold in different markets and very often, products with incomplete data. So we asked ourselves the question: how can we get even more information about a given product?
In this article, we want to share some details about one of the approaches we decided to create - The Product Similarity Catalog.
The idea was quite simple - let's create a graph of products in which similar products are connected to each other. If a given product has no information, we can always see if we can find such information from its "neighbors".
Product similarity catalog
We started our designing with few assumptions:
- Each product can have any attribute
- One product can have the same attribute added more than once for data from different sources (e.g. same product is sold on both Amazon and eBay)
- Similar products should be connected with each other
- Each relationship is enriched with additional information such as confidence and its source
- Relationships are saved permanently, not dynamically calculated
- Products and their relationships can be easily updated
Given the above assumptions, the use of a graph database was a natural solution. As part of our tests, we used one of the most popular implementations of graph databases - neo4j. But in practice, this approach did not work...
The main element of the product which carries the most information, is its title. Our tests resulted in that the full-text search support in neo4j turned out to be too slow to achieve satisfactory results. Despite the use of full-text search, the performance of this solution was incomparably worse than using a relational database. For example, we encountered problems with parallelizing access to full-text search, even though neo4j itself is very well parallel for standard queries.
For this reason we decided to use a relational database - PostgreSQL, which was used to store attributes and relationships between the products, together with a full-text search engine - Elasticsearch, which was used to index the product titles.
Similarity
How can we define the similarity between the products? As we wrote earlier, products are defined by a set of attributes, e.g. title, description, photo, price. But if two products have the same price, is it enough to consider them as similar? What about identical titles? And what if many features are similar but only slightly?
It seemed impossible to make a clear decision on our own, so we decided to use machine learning for this. Our goal was to create a universal model that will allow us to compare products described by any set of features and compute the degree of similarity of those products.
Product structure
We will start describing how our model works by defining several formalisms that will be useful in the latter part of this article.
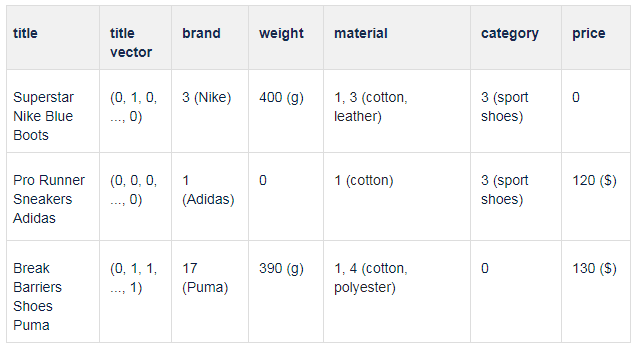
Each product will be defined by a pair of:
- title vector - created using a text vectorization approach or an embedding
- attribute vector - with a dimension equal to all possible attributes. Notice all categorical values are converted to a numerical form.
Similarity vector
A comparison of two products is defined as a vector in which each element contains a comparison of one of the product's attributes. Attributes are compared only if they appear in both products, otherwise the value is 0. How do you compare specific attributes? It depends on their type (see Table 2).
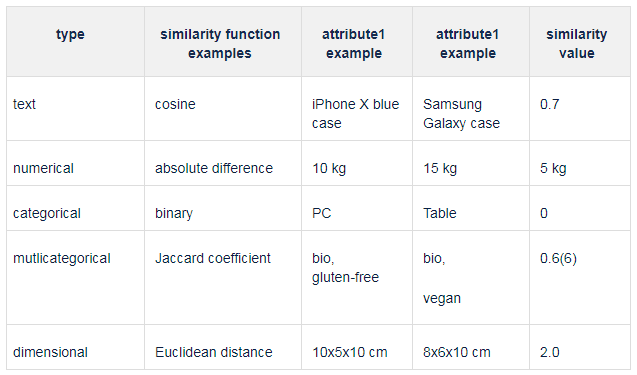
Of course, other approaches are also possible. The key idea here is to express different products as a vector containing similarities of their attributes. Methods for calculating similarity for specific attributes may vary. For example, here we compute the similarity of the category of two products binary (1, if the same categories are the same, 0 if different). But maybe is some cases, it is possible to achieve better results by computing the similarity as e.g. the length of the shortest path connecting these categories in your product categories taxonomy.
Similarity model
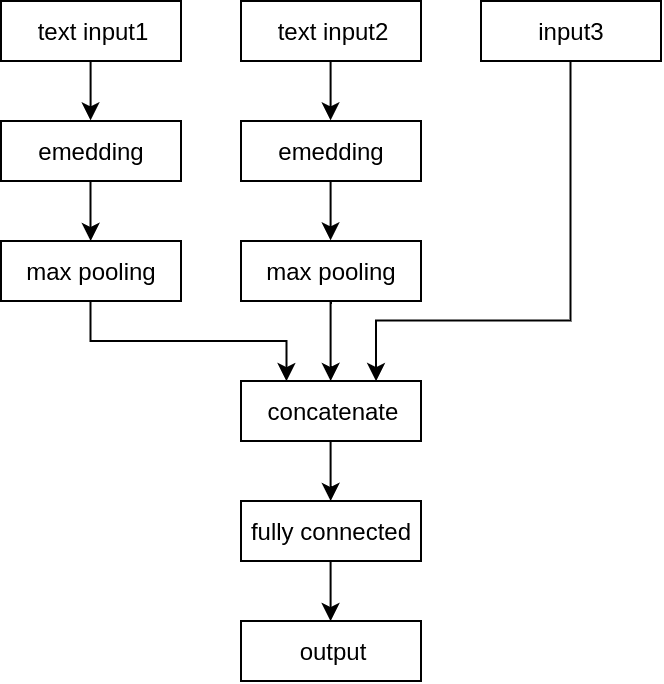
The goal of the similarity model is to compute the degree of similarity of two products based on the similarity vector described above. The model input is, therefore the similarity vector, while the output is 0-1 value which represents the similarity between products. We decided to implement the model in the form of a simple neural network consisting only of fully connected layers.
Although the information about the text data is described as a part of the similarity vector, in practice we have achieved the best results by extending the input with both titles in vector form. The text input was additionally processed by embedding and max-pooling layers (see Chart 1). So our network was built as follows:
Model optimization
It would take a long time to compute the similarity of pairs for all of the millions of products in our database. That is why we decided to use an approach known from multi-stage ranking (used e.g. in eBay's product search engine) and divided our model into two stages:
Stage 1 - full-text search
In the first step, only the product title is used. The titles of all products are indexed in the search engine (in our case it was Elasticsearch). For the selected query title, the search engine returns N most similar products which are then used in the next stage of this process.
Stage 2 - similarity model
In the next stage, we use the similarity model to calculate the similarity between the query product and each product selected during the previous stage.
Training
During our test, we used a collection of over 10 million pairs of products. The reference degree of similarity was determined based on the product leaf category (in the product taxonomy tree) - two products were marked as similar if they had the same leaf category.
The first tests showed that extending the search engine with an additional similarity model, resulted in a significant improvement in results. Because of this, we decided to perform some additional tests on our real-life problems to check the usability of the model:
Tests
Test 1 - Classification
We started by creating a kNN model for classification. In this test, our goal was to match each product to one of over 5000 categories.
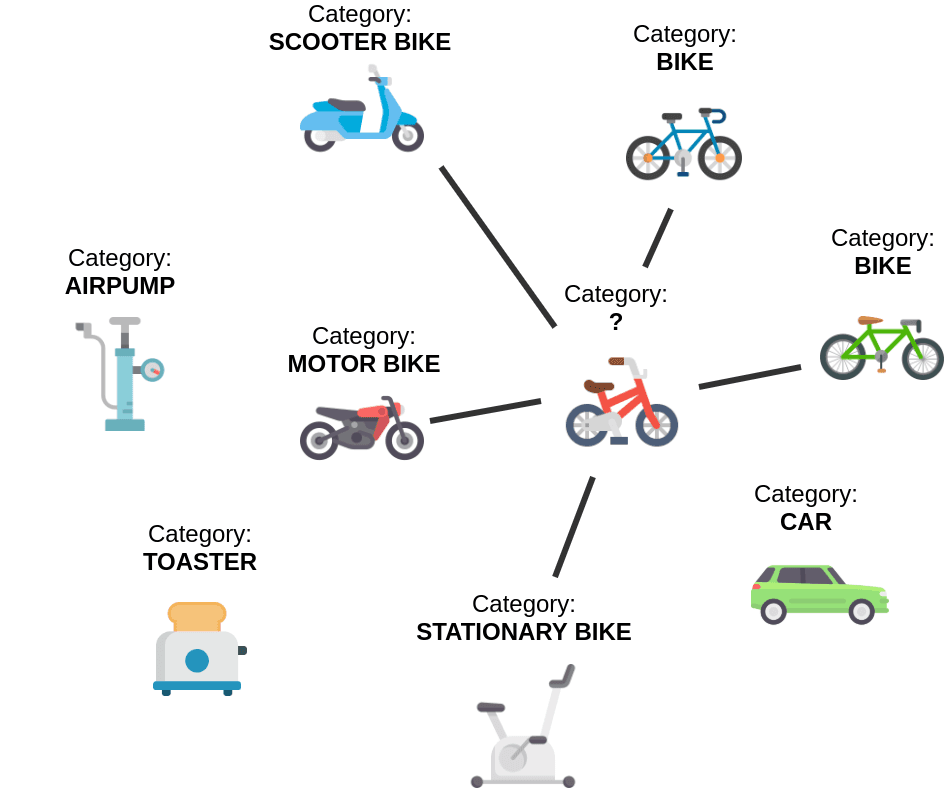
We filled our product similarity catalog with products that contained a category attribute (see Chart 2). Then, for each of the products from the test set, we used our model to estimate the appropriate category:
- Use product title to find its neighborhood (top N similar products) using full-text search engine
- Use the similarity model to compute the similarity between the input product and each product from the neighborhood
- Use weighted voting to select the most popular category in the neighborhood
- Each neighbor product votes for one category
- Vote of the neighbors with higher similarity is more important
- Category with the most votes is selected as a prediction
This model obtained results comparable to the dedicated neural network we use in production.
However, in this case, the creation of a model using the product similarity catalog was much faster.
Test 2 - Regression
Then we decided to check if exactly the same model can be used with continuous data (regression model). The problem we tested was estimating the weight of the object based on its description and attributes.
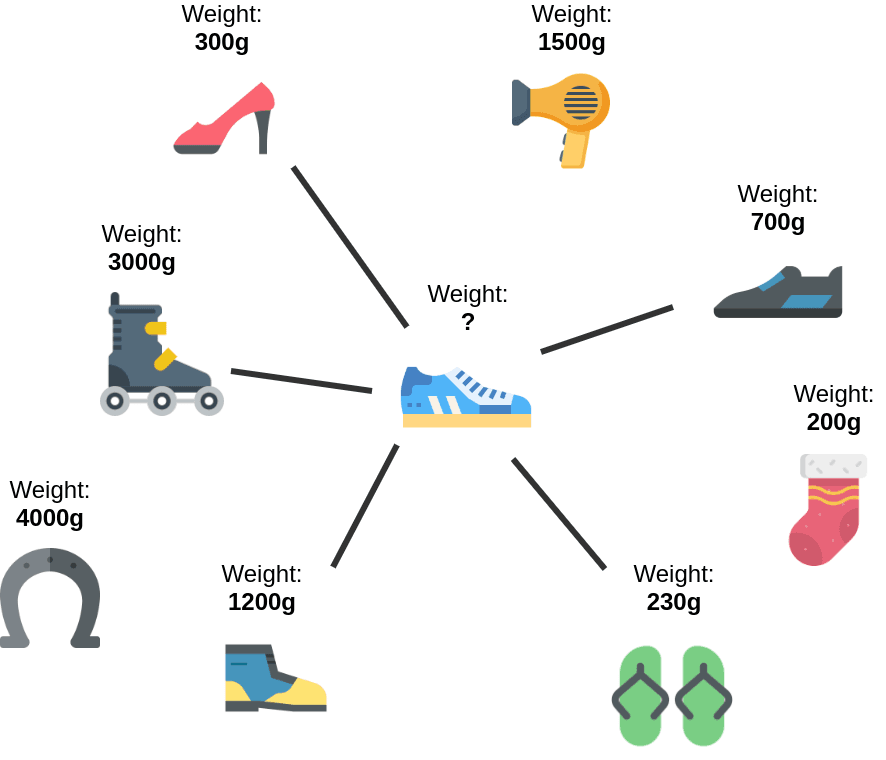
In this experiment, the product in the product similarity catalog contained information on its weight (see Chart 3).
However, in contrast to the classification, "voting" for a continuous value looks a little bit different. We decided to use a weighted average, where the value from the neighbors is weighted by the degree of similarity to the input product:
- Use the product's title to find its neighborhood (top N similar products) using full-text search engine
- Use the similarity model to compute the similarity between the input product and each product from the neighborhood
- Use a weighted average to estimate an average weight estimation
- Each neighbor product "votes" with its weight
- Each "vote" is weighted using the degree of similarity to the input product
- We use the harmonic mean to minimize the influence of outliers
- The final value is used as a prediction
Test 3 - Data analysis
During this test, we wanted to explore other uses of this model. The purpose of this test was to check whether we are able to examine and compare the quality of datasets used in previous tests. As part of this test, we tested the level of agreement between products in neighborhoods, so for each product in the neighborhood, we know how many products have the same attribute value.
As an agreement metric, we used the percentage share of the most popular value in a given group. Thus:
- If all products had the same value then the agreement of the given group was 1.
- If each object had a different answer, the match was 0
- In other cases, this value is calculated proportionally
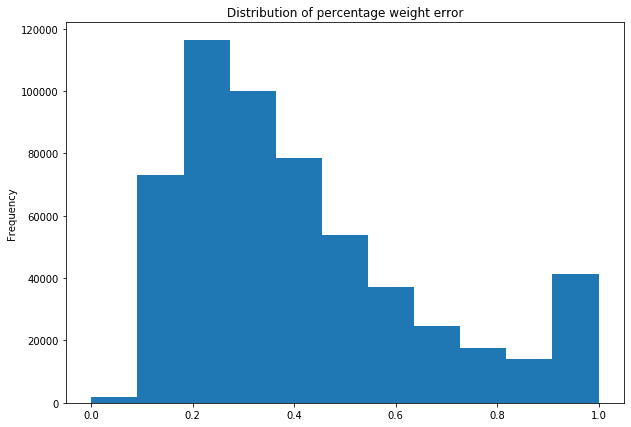
In the case of categorical data analysis, computing the agreement was simple. However, when calculating agreement for continuous data, this approach needed to be modified. So we decided to add a margin for which two continuous values are considered consistent (e.g. <20% difference). Next, we analyzed the distribution of calculated agreement in both sets:
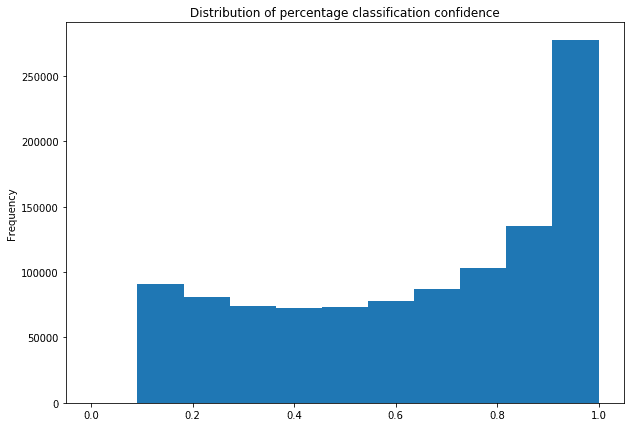
As you can see, the agreement of our categorical data (see Plot 1) was relatively high, which was also seen in a very well-functioning model created based on this data.
For continuous data used for the weight estimation problem (see Plot 2), the distribution of agreement is a lot of worst. In the case of this model, the quality was much less satisfactory than in the case of the first model. We performed further analysis manually, which confirmed the poor quality of the values for this attribute in our dataset.
Application
The product similarity catalog is used to solve many different problems popular in the e-commerce industry.
Storing data
The most basic and obvious function is simply storing data in a structured form. The product similarity catalog is created, so products sharing the same attribute are automatically connected. This way we can easily combine product information from different sources using shared attributes (e.g. using GTIN to join data from eBay and Amazon)
Analyzing data
Because products are stored in the form of a connected graph, we can easily use it to perform analysis like clustering similar products and verifying the consistency of the dataset. Because relationships between products are stored in a database and not dynamically calculated, the catalog allows you to quickly perform various analyzes.
Creating models
Product similarity catalog can be used to create a variety of universal models, that may be useful for tasks such as product title classification, product recommendation or attribute estimation (e.g. weight). Of course, creating a dedicated model can give better results, but the advantage of this approach is the ability to quickly verify the hypothesis and baseline design for more complex models
Bibliography
This problem was also a topic of scientific research. Possible solutions have been described in many scientific articles:
- The Architecture of eBay Search
- Deep Learning for Entity Matching: A Design Space Exploration
- Extracting Attribute-Value Pairs from Product Specifications on the Web
- A Machine Learning Approach for Product Matching and Categorization
- Finding Similar Products in E-commerce Sites Based on Attributes
The University of Mannheim created Gold Standard for Product Matching and Product Feature Extraction and many other useful resources that can be useful while working on your own solutions.
All resources are public and available for free at Web Data Commons. All used icons available on flaticon.
Newsletter

