
Introduction
Our story begins in 2012, when WebInterpret's core application was responsible for a lot of asynchronous operations — mostly connecting to external services (e.g. eBay.com). We needed a background mechanism that would allow background operations and api calls.
Options
In early development it became apparent that we had 3 options:
1. Use a ready, open source solution for managing asynchronous tasks (e.g. Celery).
2. Develop our own solution and maintain it using our development resources.
3. Develop our own solution and create a community around our code (open source).
The first solution is pretty common. There is a big chance that new developers will have experience with the open source solution; there are usually big communities, documentation (not always), and you can always contribute yourself if you find functionality to be lacking. The software is well tested by a global community and if you find a problem you have a chance of getting help from the community.
The second solution is pretty good when this is going to be at the core of your application, a part of the system that you are going to be selling to your customers. Nobody can use it. You have the control. And you can monetize it.
And the last one, the holy grail of software engineering, is to let the community do the work for you. There are numerous examples of this happening around the world, ranging from the biggest companies like Google, with tensorflow, to smaller libraries like bravado by Yelp. The community is going to test your code, use it and, if they require some lacking functionality, they may even contribute to it.
In early 2012 Celery was in version 2.5 and although most of the features we required were available in this version, we also needed a unique task mechanism, so WebInterpret decided to implement it's own solution - WIMQ. Below I'm going to compare it to Celery, but there are a lot of other frameworks I could have used for comparison, and which also have interesting features.
Real Example
We built our solution, called WIMQ, in 3 months. In the first implementation it composed a part of our main project. In 2014, when the company started growing and there was a need for WIMQ to be used in other projects, it was changed to a standalone package. We continued to add features until we had met all our functionality needs, after which development of WIMQ ceased (aside from bugfixing and small improvements). Other solutions, like Celery, are still being improved: contributors from all over the world are creating code.
WIMQ doesn't offer a lot of useful functionality:
No built-in support for workflows
No monitoring tools
No built-in result backend (you need to store all results manually)
Only one message queue broker supported
WIMQ has one killer feature though: it can assure that we have unique messages in the queue. But here again the open source community can pack a punch: there is a plugin for Celery which does exactly the same thing!
So maybe performance, speed or memory usage is better? Let's look at some test results
Benchmark (WIMQ vs. Celery)
First of all, how did I test both frameworks? I created 2 simple tasks which used the same code for adding 2 numbers and saving them to the db. The Celery code is:
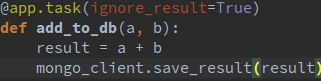
WIMQ code of the worker:

Then I produced batches of 1000, 10,000 and 50,000 tasks.
I turned off dead-letter for both workers, set prefetch_count to 100 and ran the code in 4 instances. Time elapsed was the timestamp difference between the first and last records in the db.
To make the battle fair I tried using similar settings on both frameworks (same number of threads, processes, same db).
For tests I used:
RabbitMQ - 3.6 (as message queue broker)
Mongo - 3.4 (for result storage)
Memcached - 1.4.36 (required for WIMQ to lock tasks)
Celery - 4.0.2
WIMQ - newest version
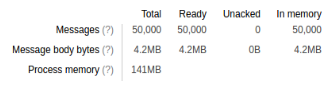
So let's start from memory usage for 50,000 simple tasks. Celery memory usage:
WIMQ results:
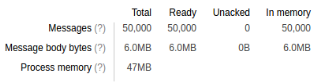
As you can see, WIMQ has a bigger message body (it stores everything in the body) while Celery, on the other hand, stores less data in the message body but uses Rabbit's headers.
Let's go to the results of the speed test. The first conclusion to be made before we even begin, is that it all depends on the settings used; I was able to make WIMQ ten times faster than Celery and vice-versa. But in the end when I found optimal and similar settings for both frameworks, I got the following results:
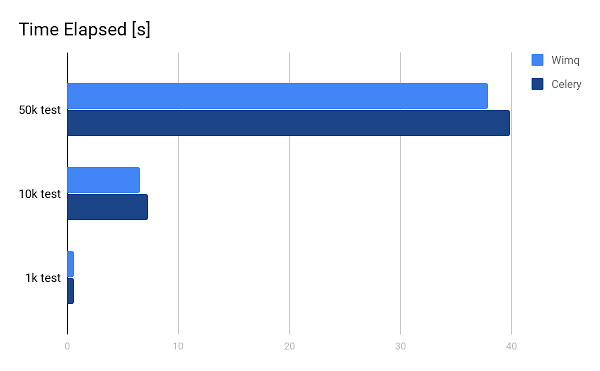
We have a winner! WIMQ was slightly faster. There were 2-3 seconds of delay for 50,000 tasks, making it around 5% faster.
Conclusions
Giving a straight answer to the question posed at the beginning of this article would involve generalizing horribly — it always depends on the case in point, but I can share some advice based on the conclusions I came to while analyzing the case above:
-
Spend some time before development to find out if there are open source solutions for your problem.
-
If you have a specific requirement that is not met by any open source solution, you should spend some time looking for plugins. If there is no plugin for your requirement, check what will be easier: developing a new solution or adding this functionality to an already existing solution.
-
Sometimes it's not worth reinventing the wheel, but if your new wheel is completely unique and you can sell it, then it is worth doing.

